LOO-CV on transformed data#
Blog post exploring whether or not LOO-CV can be used to compare models that try to explain some data \(y\) with models trying to explain the same data after a transformation \(z=f(y)\). Inspired by @tiagocc question on Stan Forums. This post has two sections, the first one is the mathematical derivation of the equations used and their application on a validation example, and the second section is a real example. In addition to the LOO-CV usage examples and explanations, another goal of this notebook is to show and highlight the capabilities of ArviZ.
import pystan
import pandas as pd
import numpy as np
import arviz as az
import matplotlib.pyplot as plt
az.style.use("arviz-darkgrid")
Mathematical derivation and validation example#
In the first example, we will compare two equivalent models:
\(y \sim \text{LogNormal}(\mu, \sigma)\)
\(\log y \sim \text{Normal}(\mu, \sigma)\)
Model definition and execution#
Define the data and execute the two models
mu = 2
sigma = 1
logy = np.random.normal(loc=mu, scale=sigma, size=30)
y = np.exp(logy) # y will then be distributed as lognormal
data = {'N': len(y), 'y': y, 'logy': logy}
Show code cell source
lognormal_code = """
data {
int<lower=0> N;
vector[N] y;
}
parameters {
real mu;
real<lower=0> sigma;
}
model {
y ~ lognormal(mu, sigma);
}
generated quantities {
vector[N] log_lik;
vector[N] y_hat;
for (i in 1:N) {
log_lik[i] = lognormal_lpdf(y[i] | mu, sigma);
y_hat[i] = lognormal_rng(mu, sigma);
}
}
"""
sm_lognormal = pystan.StanModel(model_code=lognormal_code)
fit_lognormal = sm_lognormal.sampling(data=data, iter=1000, chains=4)
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_af04dcd0464f65fe0e5bbc595b4eb9d6 NOW.
idata_lognormal = az.from_pystan(
posterior=fit_lognormal,
posterior_predictive='y_hat',
observed_data=['y'],
log_likelihood={'y': 'log_lik'},
)
Show code cell source
normal_on_log_code = """
data {
int<lower=0> N;
vector[N] logy;
}
parameters {
real mu;
real<lower=0> sigma;
}
model {
logy ~ normal(mu, sigma);
}
generated quantities {
vector[N] log_lik;
vector[N] logy_hat;
for (i in 1:N) {
log_lik[i] = normal_lpdf(logy[i] | mu, sigma);
logy_hat[i] = normal_rng(mu, sigma);
}
}
"""
sm_normal = pystan.StanModel(model_code=normal_on_log_code)
fit_normal = sm_normal.sampling(data=data, iter=1000, chains=4)
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_acd7c874588f1c862727f931f4dbf916 NOW.
idata_normal = az.from_pystan(
posterior=fit_normal,
posterior_predictive='logy_hat',
observed_data=['logy'],
log_likelihood={'logy': 'log_lik'},
)
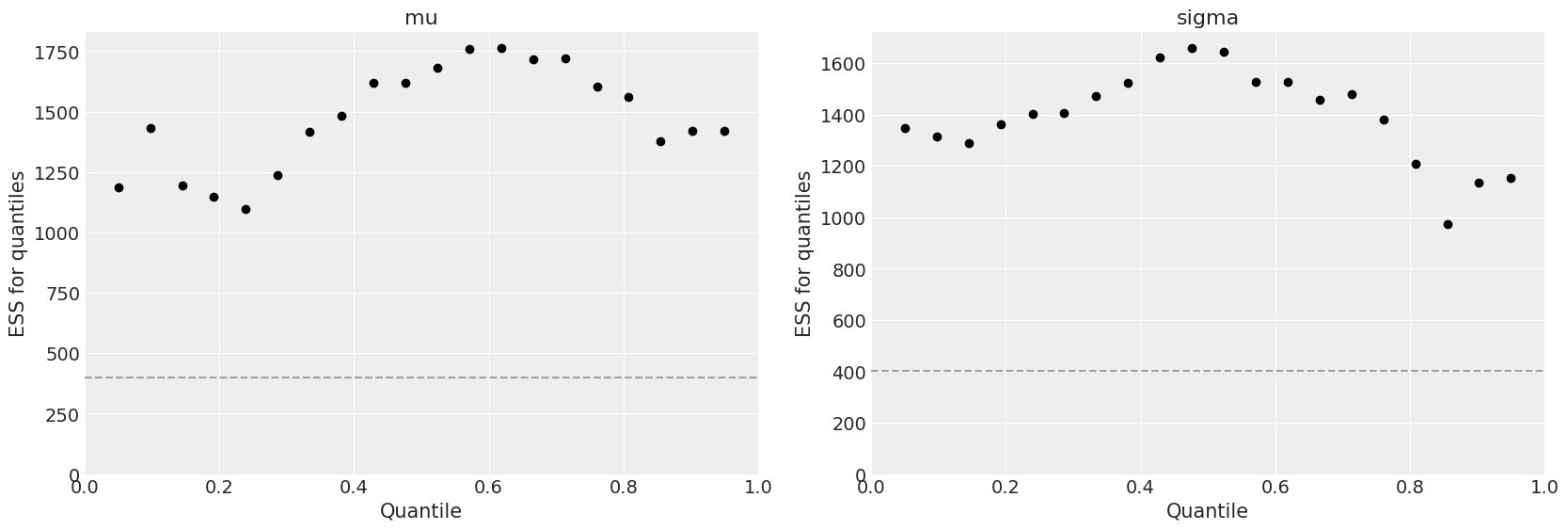
Check model convergence. Use az.summary to in one view that the effective sample size (ESS) is large enough and \(\hat{R}\) is close to one.
az.summary(idata_lognormal)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| mu | 1.857 | 0.210 | 1.485 | 2.259 | 0.005 | 0.004 | 1533.0 | 1526.0 | 1535.0 | 1483.0 | 1.0 |
| sigma | 1.145 | 0.164 | 0.853 | 1.451 | 0.005 | 0.004 | 1103.0 | 1046.0 | 1195.0 | 929.0 | 1.0 |
az.summary(idata_normal)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_mean | ess_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| mu | 1.854 | 0.205 | 1.448 | 2.222 | 0.005 | 0.004 | 1456.0 | 1456.0 | 1446.0 | 1187.0 | 1.0 |
| sigma | 1.138 | 0.155 | 0.862 | 1.420 | 0.004 | 0.003 | 1196.0 | 1070.0 | 1312.0 | 1154.0 | 1.0 |
In addition, we can plot the quantile ESS plot for one of them directly with plot_ess
az.plot_ess(idata_normal, kind="quantile", color="k");
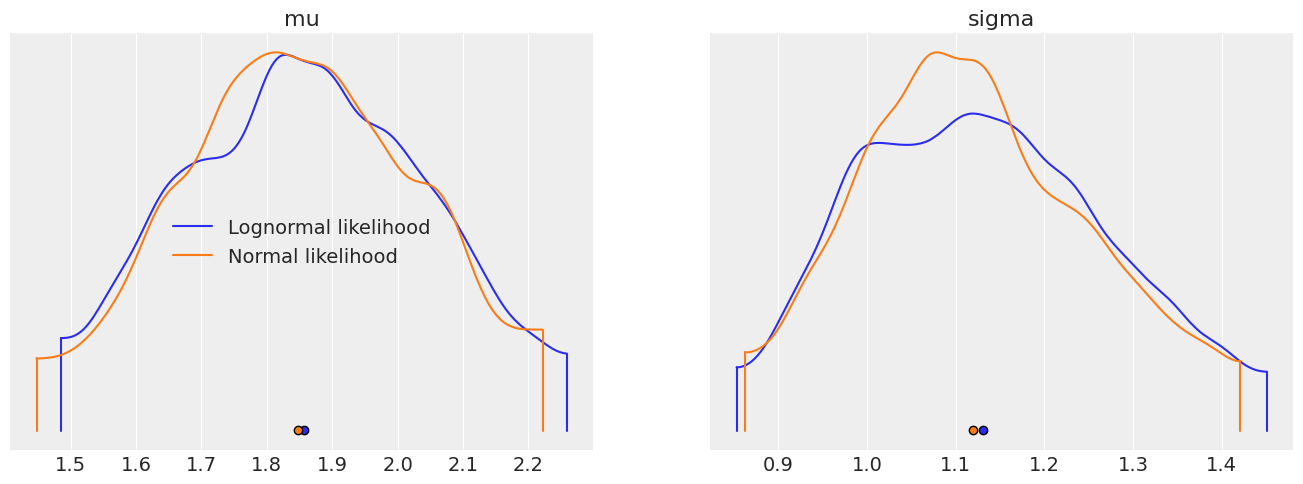
Posterior validation#
Check that both models are equivalent and do indeed give the same result for both parameters.
az.plot_density([idata_lognormal, idata_normal], data_labels=["Lognormal likelihood", "Normal likelihood"]);
Calculate LOO-CV#
Now we get to calculate LOO-CV using Pareto Smoothed Importance Sampling as detailed in Vehtari et al., 2017. As we explained above, both models are equivalent, but one is in terms of \(y\) and the other in terms of \(\log y\). Therefore, their likelihoods will be on different scales, and hence, their expected log predictive density will also be different.
az.loo(idata_lognormal)
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -102.50 7.28
p_loo 1.80 -
az.loo(idata_normal)
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -46.57 3.46
p_loo 1.64 -
We have found that as expected, the two models yield different results despite being actually the same model. This is because. LOO is estimated from the log likelihood, \(\log p(y_i\mid\theta^s)\), being \(i\) the observation id, and \(s\) the MCMC sample id. Following Vehtari et al., 2017, this log likelihood is used to calculate the PSIS weights and to estimate the expected log pointwise predictive density in the following way:
Calculate raw importance weights: \(r_i^s = \frac{1}{p(y_i\mid\theta^s)}\)
Smooth the \(r_i^s\) (see original paper for details) to get the PSIS weights \(w_i^s\)
Calculate elpd LOO as:
This will estimate the out of sample predictive fit of \(y\) (where \(y\) is the data of the model. Therefore, for the first model, using a LogNormal distribution, we are indeed calculating the desired quantity:
Whereas for the second model, we are calculating:
being \(z_i = \log y_i\). We actually have two different probability density functions, one over \(y\) which from here on we will note \(p_y(y)\), and \(p_z(z)\).
In order to estimate the elpd loo for \(y\) from the data in the second model, \(z\), we have to describe \(p_y(y)\) as a function of \(z\) and \(p_z(z)\). We know that \(y\) and \(z\) are actually related, and we can use this relation to find how would the random variable \(y\) (which is actually a transformation of the random variable \(z\)) be distributed. This is done with the Jacobian. Therefore:
In the log scale:
We apply the results to the log likelihood data of the second model (the normal on the logarithm instead of the lognormal) and check that now the result does coincide with the LOO-CV estimated by the lognormal model.
z = logy
idata_normal.log_likelihood["y"] = -z+idata_normal.log_likelihood.logy
az.loo(idata_normal, var_name="y")
Computed from 2000 by 30 log-likelihood matrix
Estimate SE
elpd_loo -102.30 7.26
p_loo 1.64 -
Real example#
We will now use as data a subsample of a real dataset. The subset has been selected using:
df = pd.read_excel("indicator breast female incidence.xlsx").set_index("Breast Female Incidence").dropna(thresh=20).T
df.to_csv("indicator_breast_female_incidence.csv")
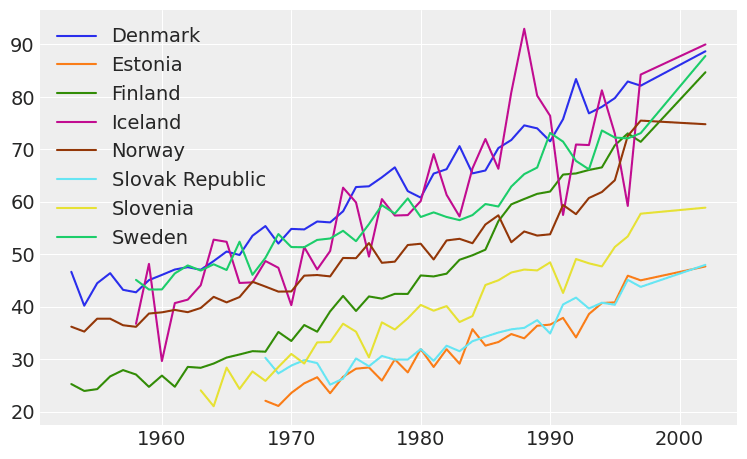
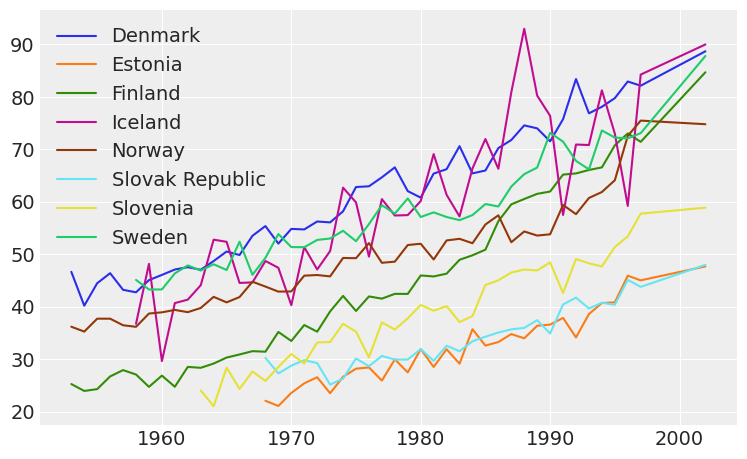
Below, the data is loaded and plotted for inspection.
df = pd.read_csv("data/indicator_breast_female_incidence.csv", index_col=0)
df.plot(figsize=(9,5.5));
In order to show different examples of LOO on transformed data, we will take into account the following models:
This models have been chosen mainly because of their simplicity. In addition, they can all be applied using the same Stan code and the data looks kind of linear. This will put the focus of the example on the loo calculation instead of on the model itself. For the online example, the data from Finland has been chosen, but feel free to download the notebook and experiment with it.
y_data = df.Finland
z1_data = np.log(y_data)
z2_data = np.sqrt(y_data)
x_data = df.index/100 # rescale to set both to a similar scale
dict_y = {"N": len(x_data), "y": y_data, "x": x_data}
dict_z1 = {"N": len(x_data), "y": z1_data, "x": x_data}
dict_z2 = {"N": len(x_data), "y": z2_data, "x": x_data}
coords = {"year": x_data}
dims = {"y": ["year"], "log_likelihood": ["year"]}
Show code cell source
lr_code = """
data {
int<lower=0> N;
vector[N] x;
vector[N] y;
}
parameters {
real b0;
real b1;
real<lower=0> sigma_e;
}
model {
b0 ~ normal(0, 20);
b1 ~ normal(0, 20);
for (i in 1:N) {
y[i] ~ normal(b0 + b1 * x[i], sigma_e);
}
}
generated quantities {
vector[N] log_lik;
vector[N] y_hat;
for (i in 1:N) {
log_lik[i] = normal_lpdf(y[i] | b0 + b1 * x[i], sigma_e);
y_hat[i] = normal_rng(b0 + b1 * x[i], sigma_e);
}
}
"""
sm_lr = pystan.StanModel(model_code=lr_code)
control = {"max_treedepth": 15}
INFO:pystan:COMPILING THE C++ CODE FOR MODEL anon_model_01dac21720941a01839c67cf2ac4a0fc NOW.
fit_y = sm_lr.sampling(data=dict_y, iter=1500, chains=6, control=control)
fit_z1 = sm_lr.sampling(data=dict_z1, iter=1500, chains=6, control=control)
fit_z2 = sm_lr.sampling(data=dict_z2, iter=1500, chains=6, control=control)
idata_y = az.from_pystan(
posterior=fit_y,
posterior_predictive='y_hat',
observed_data=['y'],
log_likelihood={'y': 'log_lik'},
coords=coords,
dims=dims,
)
idata_y.posterior = idata_y.posterior.rename({"b0": "a0", "b1": "a1"})
idata_z1 = az.from_pystan(
posterior=fit_z1,
posterior_predictive='y_hat',
observed_data=['y'],
log_likelihood={'z1': 'log_lik'},
coords=coords,
dims=dims,
)
idata_z2 = az.from_pystan(
posterior=fit_z2,
posterior_predictive='y_hat',
observed_data=['y'],
log_likelihood={'z2': 'log_lik'},
coords=coords,
dims=dims,
)
idata_z2.posterior = idata_z2.posterior.rename({"b0": "c0", "b1": "c1"})
In order to compare the out of sample predictive accuracy, we have to apply the Jacobian transformation to the 2 latter models, so that all of them are in terms of \(y\).
Note: we will use LOO instead of Leave Future Out algorithm even though it may be more appropriate because the Jacobian transformation to be applied is the same in both cases. Moreover, PSIS-LOO does not require refitting, and it is already implemented in ArviZ.
The transformation to apply to the second model \(z_1 = \log y\) is the same as the previous example:
idata_z1.log_likelihood["y"] = -z1_data.values+idata_z1.log_likelihood.z1
In the case of the third model, \(z_2 = \sqrt{y}\):
idata_z2.log_likelihood["y"] = -np.log(2*z2_data.values)+idata_z2.log_likelihood.z2
az.loo(idata_y)
Computed from 4500 by 46 log-likelihood matrix
Estimate SE
elpd_loo -194.26 3.83
p_loo 1.58 -
LOO before Jacobian transformation: 70.56
Computed from 4500 by 46 log-likelihood matrix
Estimate SE
elpd_loo -100.44 4.47
p_loo 3.14 -
References#
Vehtari, A., Gelman, A., and Gabry, J. (2017): Practical Bayesian Model Evaluation Using Leave-One-OutCross-Validation and WAIC, Statistics and Computing, vol. 27(5), pp. 1413–1432.
Comments are not enabled for the blog, to inquiry further about the contents of the post, ask on ArviZ Issues or Stan Discourse